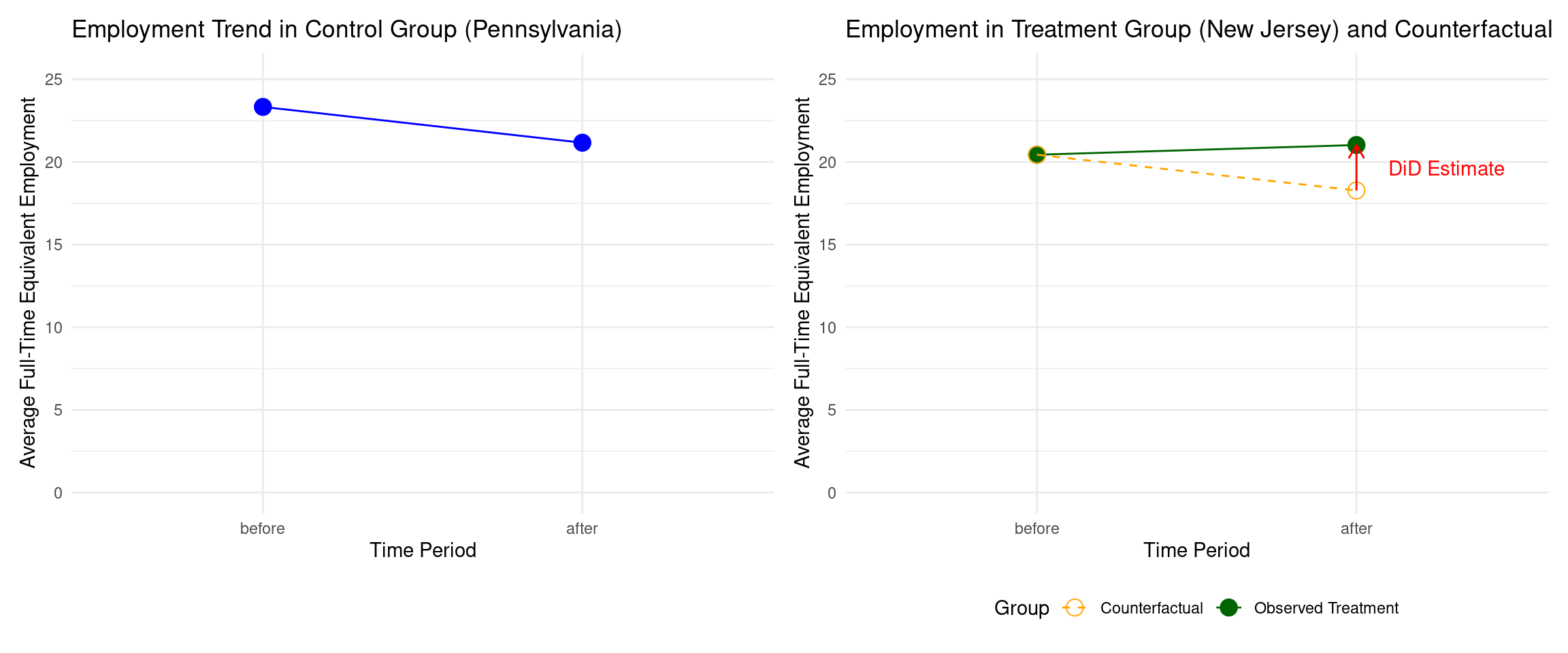
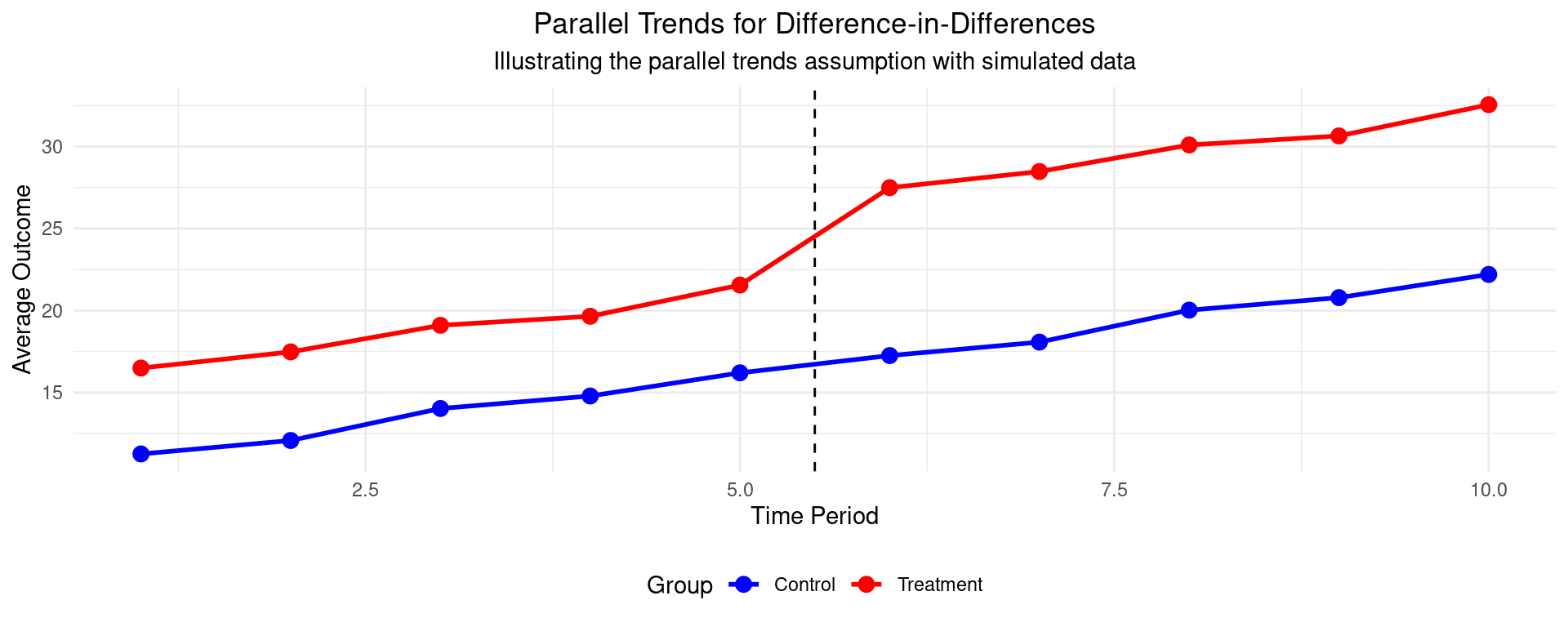
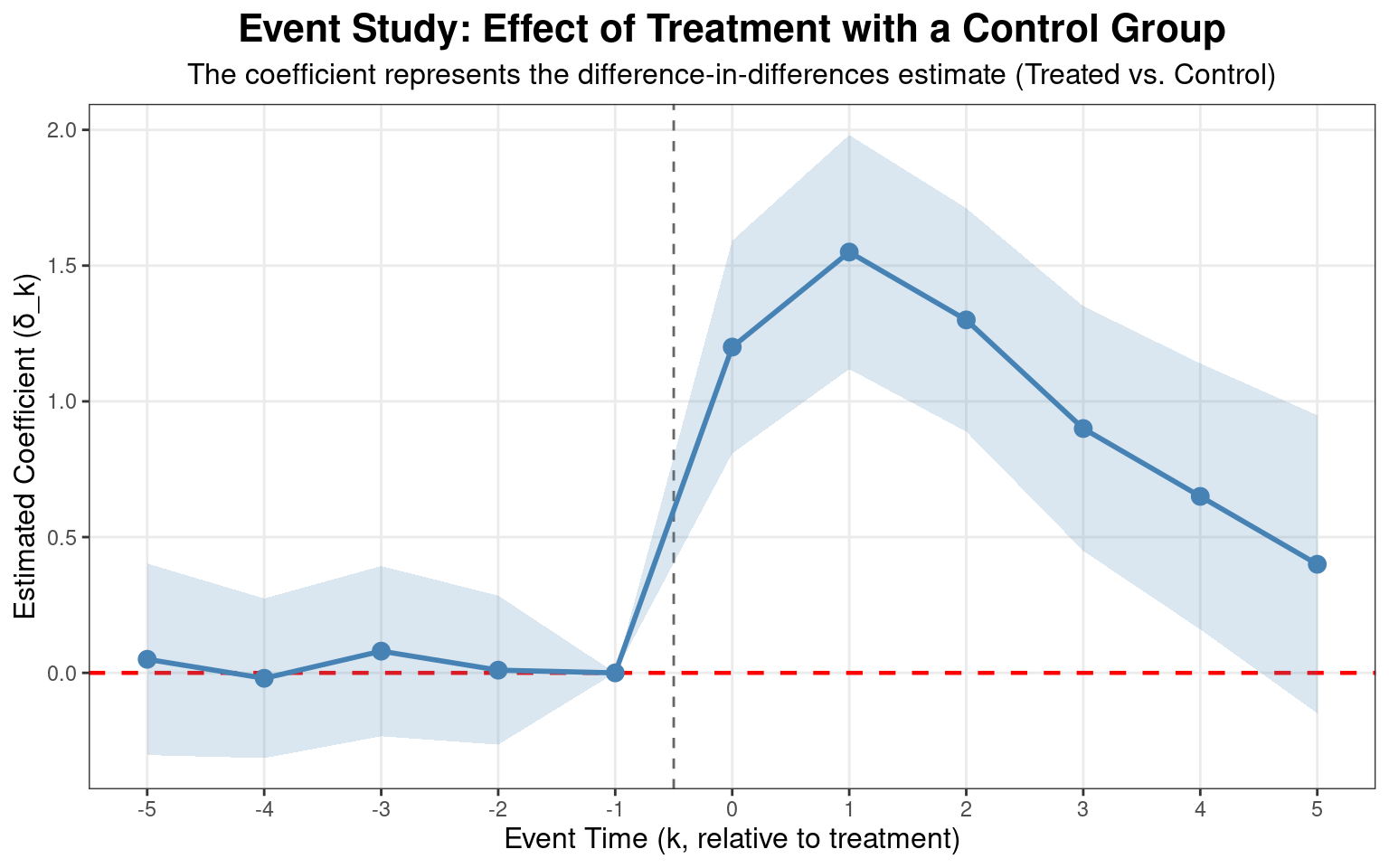
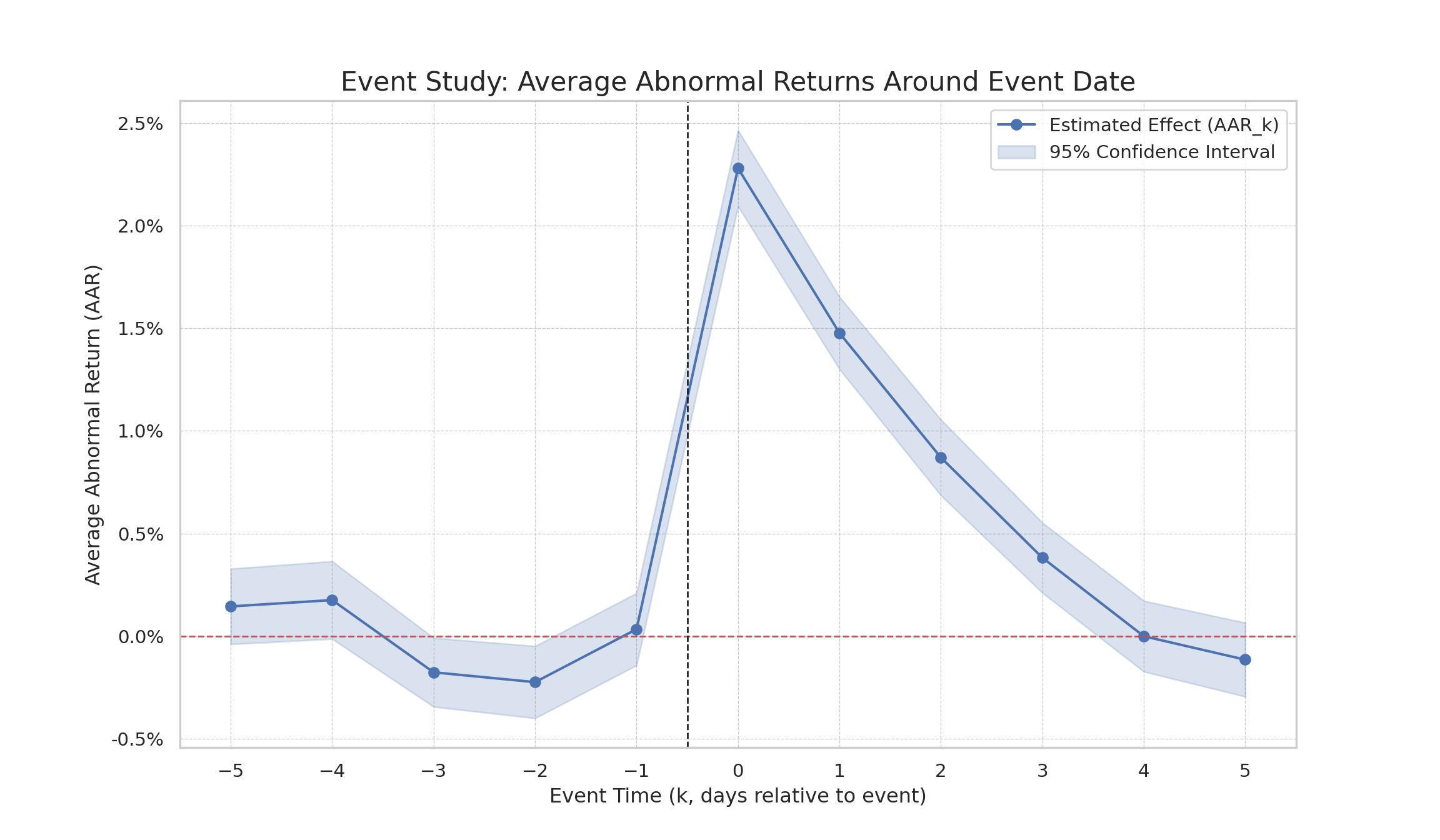
Code
library(tidyverse); library(fixest)
file_url <- "https://github.com/mca91/EconometricsWithR/blob/master/data/fastfood.dta?raw=true"
card_krueger_data <- foreign::read.dta(file_url) |> as_tibble()
head(card_krueger_data)
## # A tibble: 6 × 46
## sheet chain co_owned state southj centralj northj pa1 pa2 shore ncalls
## <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 46 1 0 0 0 0 0 1 0 0 0
## 2 49 2 0 0 0 0 0 1 0 0 0
## 3 506 2 1 0 0 0 0 1 0 0 0
## 4 56 4 1 0 0 0 0 1 0 0 0
## 5 61 4 1 0 0 0 0 1 0 0 0
## 6 62 4 1 0 0 0 0 1 0 0 2
## # ℹ 35 more variables: empft <dbl>, emppt <dbl>, nmgrs <dbl>, wage_st <dbl>,
## # inctime <dbl>, firstinc <dbl>, bonus <int>, pctaff <dbl>, meals <int>,
## # open <dbl>, hrsopen <dbl>, psoda <dbl>, pfry <dbl>, pentree <dbl>,
## # nregs <int>, nregs11 <int>, type2 <int>, status2 <int>, date2 <int>,
## # ncalls2 <int>, empft2 <dbl>, emppt2 <dbl>, nmgrs2 <dbl>, wage_st2 <dbl>,
## # inctime2 <int>, firstin2 <dbl>, special2 <int>, meals2 <int>, open2r <dbl>,
## # hrsopen2 <dbl>, psoda2 <dbl>, pfry2 <dbl>, pentree2 <dbl>, nregs2 <int>, …